商机详情 -
数据使用区
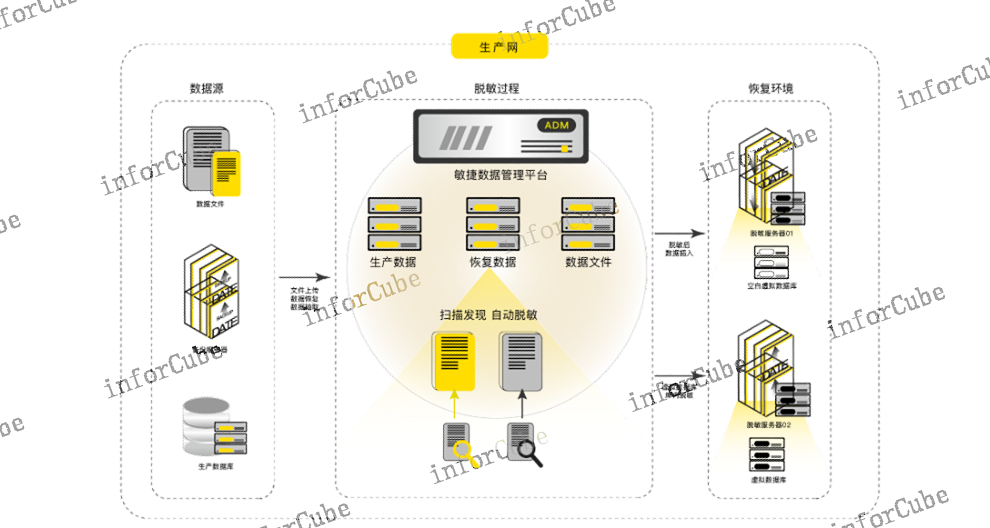
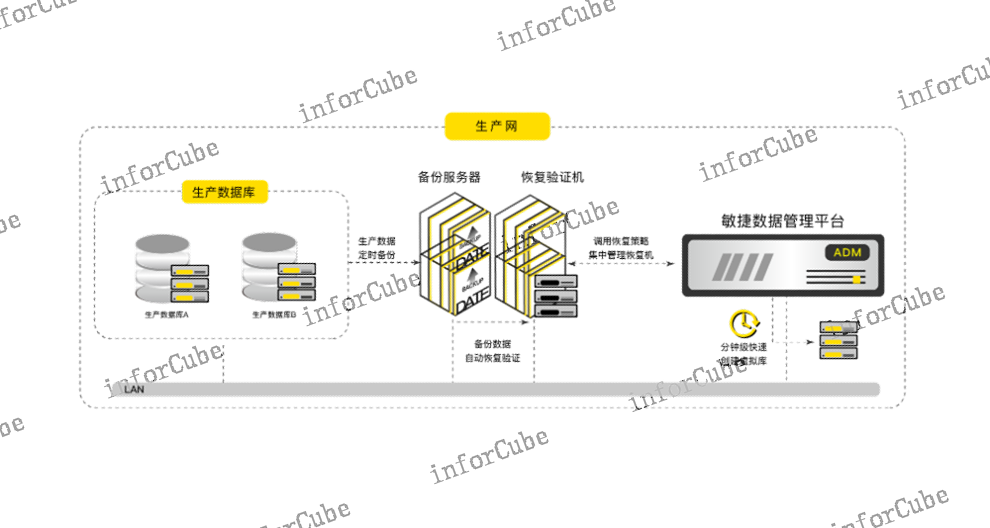
(1)国产化数据备份系统兼容性不足当前国产化数据保护系统对国产化数据库、文件、虚拟化平台、容器、云服务器等备份源类型兼容不***,适配过程中需要更多的时间进行功能稳定性验证。(2)数据备份恢复验证耗时耗力当前采用NetBackup等集中备份系统备份的数据需采用手动恢复数据,过程繁琐、重复度高、专业性强,耗费大量的时间和人力成本。(3)数据交付时间长不论是通过数据恢复还是数据拷贝来提供测试数据,需要几小时到几周的时间。(4)占用大量存储资源数以千计的数据副本占用大量存储资源,需要更多的维护成本。(5)数据版本回退困难开发、测试环境中,当完成一轮跑批测试或功能调试后,重置数据状态需要重新导入数据或重新恢复数据,回退数据产生的时间成本巨大。(6)数据安全风险真实数据被用于测试使用后无法及时回收和销毁,造成资源浪费,存在敏感信息泄露的安全风险。(7)敏感数据安全隐患生产数据库中存在着大量的敏感信息,传统的手工***效率低、仿真度差、***不完全,交付给测试环境后存在隐私泄漏的风险。目前,ADM备份数据恢复验证管理功能实现了按计划设定备份恢复任务并自动执行,无需手动操作。数据使用区
国内在CDM(Copy Data Management,拷贝数据管理)技术上的发展较为迅速,涌现出几家领*的厂商。其中,上讯信息、爱数和鼎甲是三家备受关注的国产备份厂商,它们已从传统的数据备份领域成功扩展到CDM领域。这些厂商在提供全*数据管理解决方案方面表现出色,通过采用先进的快照技术和数据虚拟化技术,实现了数据的高效备份、恢复和快速分发,满足了不同行业在数字化转型过程中的数据管理需求。上讯信息更是以其基于CDM技术的测试基准数据快速交付方案而知*,特别适用于银行业软件开发测试中心,解决了测试环境搭建中数据准备与交付的瓶颈问题。压缩存储池ADM可对虚拟副本拍摄快照实现数据副本状态的保留进行灵活的数据版本管理,适用于数据库和文件。
ADM平台具备根据管理人员、测试需求等内容的不同进行分组划分的功能,将处理过的数据进行分组管理,从下游测试数据管理的源头管控数据资源的类别,做到从源头划分类别,使下游测试数据管理形成上游数据源-中游数据中转-下游数据目标的闭环式数据使用流程,规范化的数据流程使数据管理者成为数据的负责人,自动化的资源管理也更有效地为金融行业用户提供安全的数据管理方案。同时,ADM提供对数据流转的树状拓扑结构图,可详细了解数据的来源、所属存储池、挂载的测试服务器,以及数据快照的层级关系,方便对系统全局的数据使用结构进行预览,通过可视化的结构拓扑图,帮助用户了解下游测试网中测试数据的归属关系,完善数据流转路径,优化数据资源的合理分配,可视化功能的动态展示将助力企业向着智能化数据安全治理的方向转型。
测试数据版本迭代管理,提升开发测试业务的变更效率企业开发需求更新频繁,对测试环境和测试数据提出了同步变更的要求,ADM的虚拟数据库快照功能解决了测试数据版本迭代的问题,通过对数据库状态进行定时或即时的记录,保留当前虚拟数据库的状态作为测试数据版本,一旦需要调用某个版本时,只需切换到不同时间点的虚拟库快照即可,灵活实现测试数据版本的任意切换,ADM还支持创建和维护虚拟库级联快照,满足回归测试等具体应用场景,通过这一功能明显提升了开发测试效率、升级迭代效率。ADM脱*功能支持保留原有数据含义的仿真型脱*规则,支持中文字典库与编码字典库。
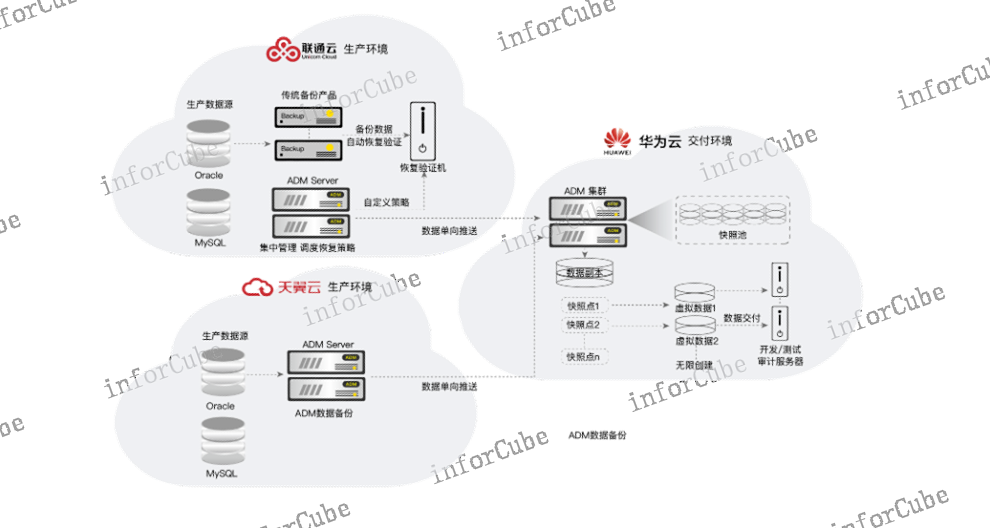
敏捷数据管理平台ADM的关键技术如下:l***数据获取方式数据获取的目的是将不同的数据源实时或者按需同步到平台内,根据不同类型的数据源,数据获取方式分为三种,保证覆盖全部数据源获取方式:①支持实时同步应用数据库;②支持按需同步关系型数据库;③支持与备份系统对接恢复数据。l核心专利技术—数据库虚拟化技术ADM内置一套数据库虚拟化管理程序,虚拟数据库是通过一份基础数据源创建的数据副本,一份基础数据源可以生成多个虚拟数据库,虚拟数据库可读可写,虚拟数据库状态可实时保存。虚拟数据库创建时间为分钟级,且不占用额外的存储空间。ADM脱*功能具备灵活的数据抽取组合方式与自助式向导脱*流程,有效降低脱*工作的复杂度。匹配度降序排列
ADM内置的智能读写缓存机制满足测试环境多场景同步测试的需求,能够满足压力测试的性能要求。数据使用区
在典型的重复数据删除技术中,根据不同的数据备份场景选择适合的重删策略与粒度方案。在确定重删策略与粒度后,会根据输入侧不同粒度(卷级、文件级、块级)的数据采取不同的数据切分策略,并依据任务级与全局指纹库提供自适应源端的全局重删算法与策略,当前支持源端块级、文件级重删和并行重删技术。源端重删是采用基于内容的可变长数据切分算法,通过对数据块进行哈希算法的***标记,即指纹(Fingerprint),在指纹库中寻找相同的指纹。如果存在相同指纹,则表示已保存了相同的数据块,ADM则不再保存此数据块,而是引用已存在的数据块,从而节省更多的备份空间。该算法还可以智能识别已修改的数据和未修改的数据,从而避免因修改数据位移而导致的未修改数据切分到新数据块中的问题,比较大限度地提升重删性能和重删率,为避免数据备份过程中冗余网络传输与存储开销,在源端设置粗粒度前置数据校验可以明显缩小备份传输过程中的数据冗余,目的在于不备份任意一个冗余数据。数据使用区