商机详情 -
分子水平药物筛选模型
创立挑选渠道多样性网格如上文针对挑选渠道的规划所述,咱们主要考虑了两个方针:方针是比较大化挑选渠道子集的多样性。生物活性空间的多样性是咱们的主要方针。对于化合物,存在大量的描述符和多样性指标,其中有些是部分剩余的。没有简单的方法能够将它们组合为一个一致的指标。因而,咱们做出的挑选是单独运用几个相关度量,以通过聚类为每个度量定义复合类。其他化合物的分类由现有的离散化合物注释产生。一旦将化合物分为生物活性和化学结构类别,多样性挑选过程的目的就是生成较小尺度的子集,确保每个类别的预设较小覆盖率。第二个方针是优化化合物的特异性和主要的理化性质,因为要考虑多种此类特点,因而需要将它们组合成一个多方针得分。这样的打分是每种化合物的单独特点,答应在单独的基础上对化合物进行比较和排名。什么是高通量筛选技能?分子水平药物筛选模型

大有可为的噬菌体抗体库基于抗体基因序列来源,噬菌体抗体库分为三大类:天然抗体库(Naveantibodylibrary),基因来源人体或动物体内的血液、骨髓、脾脏和扁桃体内的B淋巴细胞。优点是可获得人抗体、针对所有天然抗原、库足够大,可直接获得高亲和力抗体,但建库耗时费力,而且存在很多未知和不可控因素。半合成抗体库(Semi-syntheticantibodylibrary)由人工合成的一部分可变区序列与另一部分天然序列组合构建而成的抗体库。其主要是使用种系的重链、轻链或重排的可变区片段,其中一个或多个CDR要随机重排。对难于在体内进行免疫的抗体研发具有良好的应用前景;镇咳药物筛选以自动化分离技能进行筛选,攻克天然药物成分提取难题。
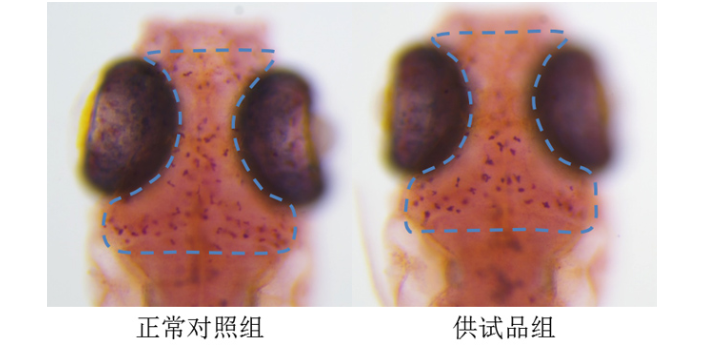
高通量挑选在100μM浓度下,运用MCEFDA批准上市库进行挑选,经过显微成像技术,终究得到16种阳性化合物(图2a)中,其中Tranilast在按捺基质堆积方面表现出杰出的作用,并呈现出剂量依赖性(图2b),并且已有文献标明Tranilast在体内具有较好的生物利费用、安全性和耐受性的安全性,终究选定Tranilast作为先导化合物。■构效联系剖析及先导化合物优化由于挑选到的Tranilast需要在较高浓度(>150μM)下才会表现出较强的抗纤维化活性,所以作者还对Tranilast做了进一步结构优化,希望从Tranilast结构类似物中挑选到具有更高活性的产品(图4a)。经过对Tranilast结构类似物及合成的一系列结构类似物做进一步挑选,得到一系列N-(2-butoxyphenyl)-3-(phenyl)acrylamides(N23Ps),部分N23Ps具有较高的抗纤维化活性,按捺ECM堆积的IC50数值在10μM以下
YanWang团队建立了一种新的基于酶联免疫吸附的办法,对1500种FDA同意上市化合物高通量挑选,获得了三种对Keap1-Nrf2蛋白相互作用按捺效果较好的小分子。■其他办法以上三种高通量挑选办法均运用荧光检测,目前还有其他非荧光途径的检测办法,在实际应用中,多种办法联合运用。例如,CarlosAlvarado团队就先后运用表面等离子共振和核磁共振技术两种检测办法,先从189个片段化合物库中挑选出19个化合物,再经过核磁共振二次挑选出11个对局灶黏附激酶的局灶黏附靶向域起作用的化合物。虚拟筛选在药物发现中的意义。
迭代化合物挑选过程如上所述,现在的方针是对界说为空间掩盖方针的类进行迭代,从每个类中挑选排名比较好的化合物样本,然后重复此循环屡次。一旦所有化合物均已按特点进行了排序并分配给不同类型的空间掩盖类别,而且已界说了每次迭代的较小簇巨细,则能够运转挑选算法以生成多样性网格2015挑选渠道和2019挑选渠道的比较图6(分子量)和图7(clogP)展现了2015年和2019年平板子集的特性曲线。2015年的挑选平板网格显现,MW<350Da的偏差很大,A和B类的clogP规模为1-3,使这些化合物简直呈碎片状。我们还发现,2015年筛查平板的A和B类命中率低于C类,即分子量和clogP规模受限会导致整个挑选的化合物多样性失衡。根据这些观察,我们决议更改2019版网格的排名标准:引入高溶解度和高渗透性作为A列的正挑选标准,而MW和clogP不再直接考虑。可是,为了同时取得杰出的浸透性和溶解性,较低的MW和clogP仍然是有利的。如图9和图10所示,与其他两列相比,2019版:高溶解度和浸透率色谱柱的MW和clogP散布已移至较低值。更重要的是,2019版的新设计还似乎对前两列和行中的化学起始点产生了积极影响。高通量筛选化合物库寻觅抑制剂的中心在于酶活性信息的获得办法。筛选药物浓度
高通量筛选技能已经不再是制药范畴的专属东西,它已经逐渐成为科研范畴进行根底研讨的重要东西。分子水平药物筛选模型
单个生物靶标类。有关单个生物靶标的生物活性数据是从咱们的内部系统“hithub”中提取的,该系统包含一切内部生物活性数据,并定期经过来自主要公共数据源(ChEMBL,ClarivateIntegrity,GOSTAR)的生物活性数据进行更新。生物化合物概括空间类。按单个靶标对化合物分组的一种补充方法是跨多个靶标或分析使用生物学谱数据。猜测配置文件是在单个目标基础上核算的,以依据pfam数据库中的蛋白质域注释取得贝叶斯活性指纹(BAFP)以及每个蛋白质家族来取得贝叶斯域指纹(BDFP)。化学空间掩盖类。NIBR开发了一种化合物骨架分类方法,称为“骨架树”,随后扩展到了“骨架网络”。该网络用于纯粹依据化学结构来界说类别。手动分类。以上一切分类都是经过核算得出的,还需要有依据化学家们的经验常识来指定的分类。分子水平药物筛选模型